Enhancing Diffusion Models with 3D Perspective Geometry Constraints
Rishi Upadhyay1 Howard Zhang1 Yunhao Ba12 Ethan Yang1 Blake Gella1 Sicheng Jiang1 Alex Wong3 Achuta Kadambi1
University of California, Los Angeles1 Sony2 Yale University3
SIGGRAPH Asia 2023, Sydney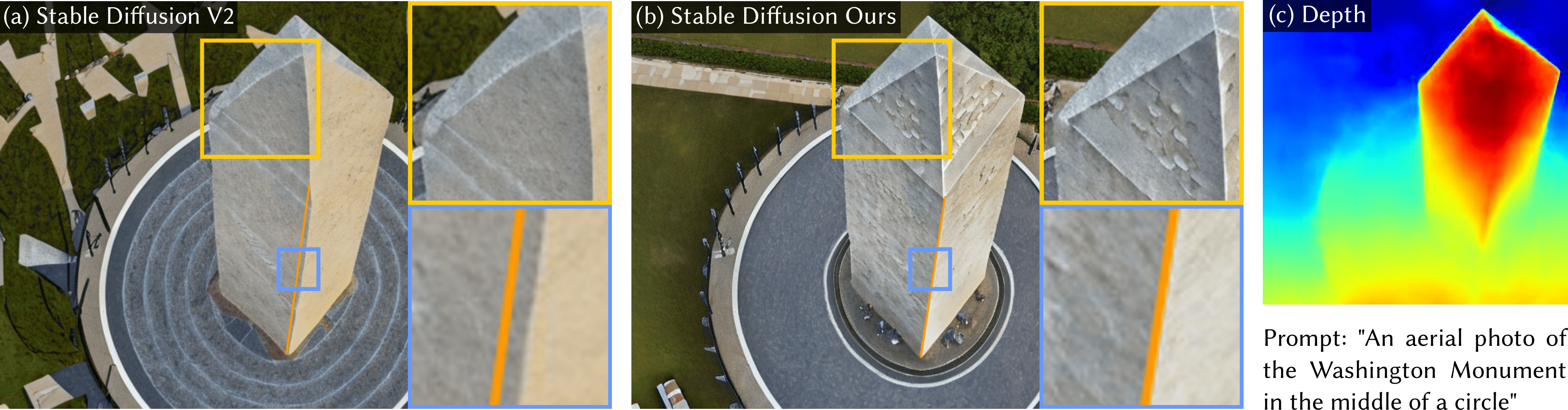
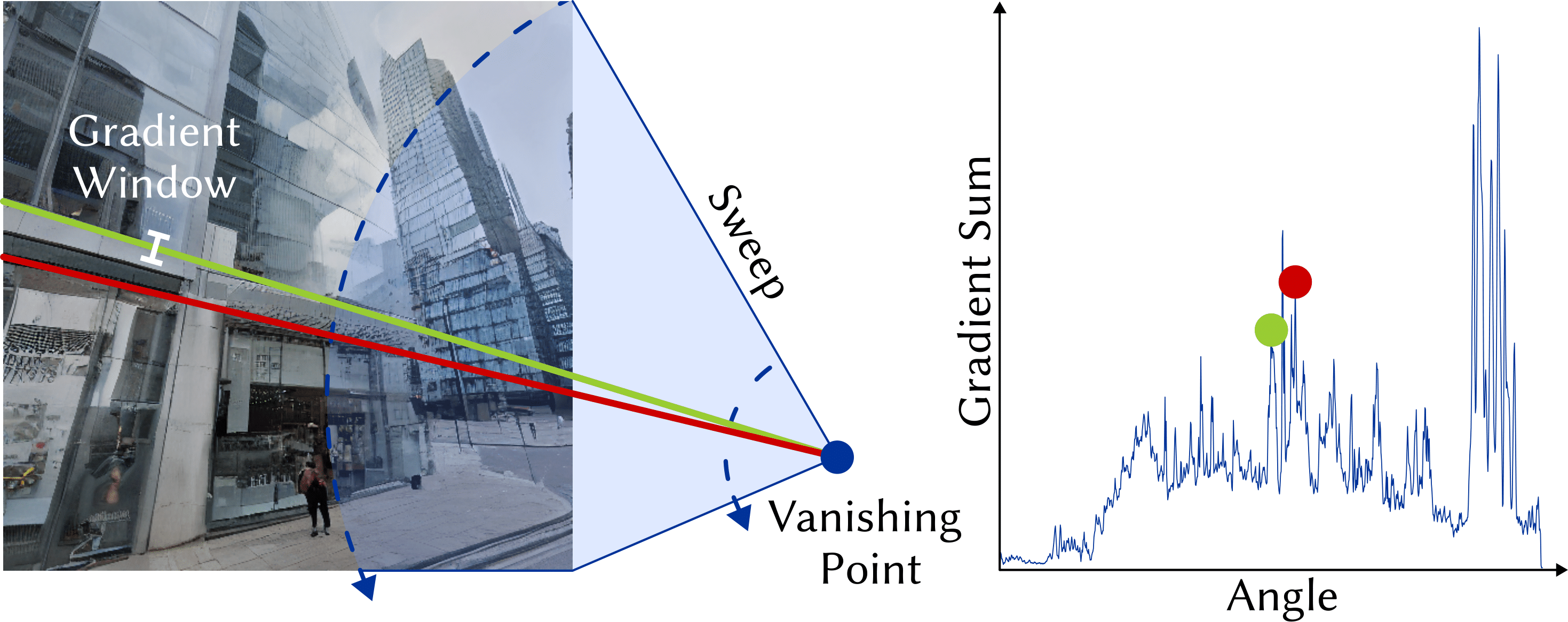
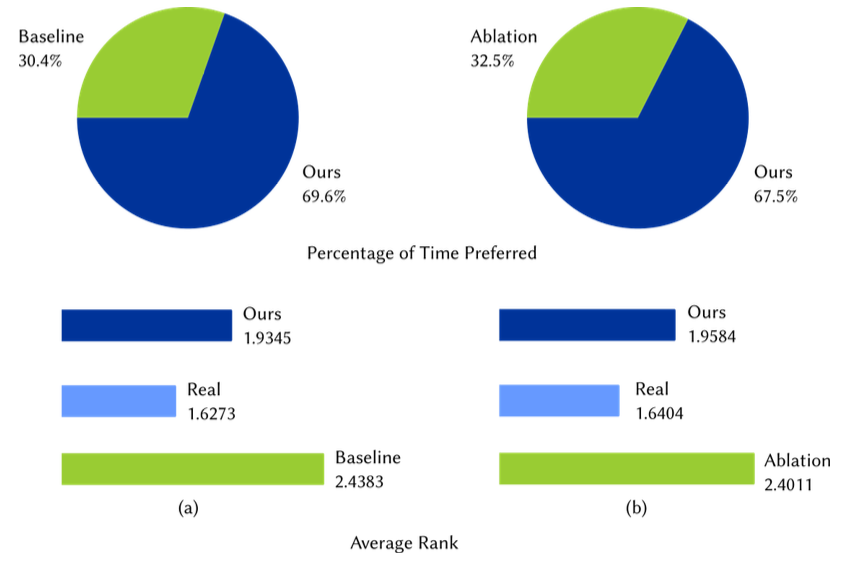
Images from our model preserve straight lines and perspective. Traditional diffusion models include no constraints on physical accuracy and rely entirely on large datasets to generate realistic images. Our proposed geometric constraint explicitly encodes perspective constraints and results in improved image generation and downstream task performance.