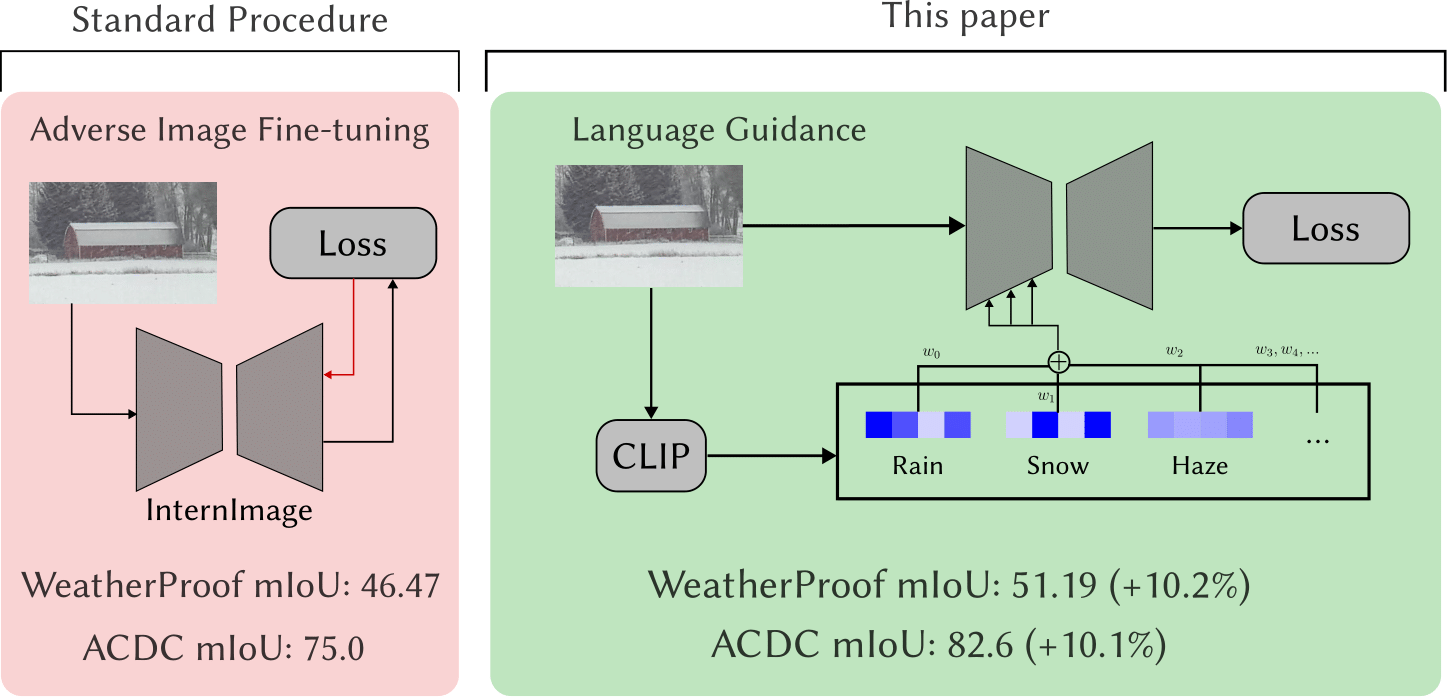
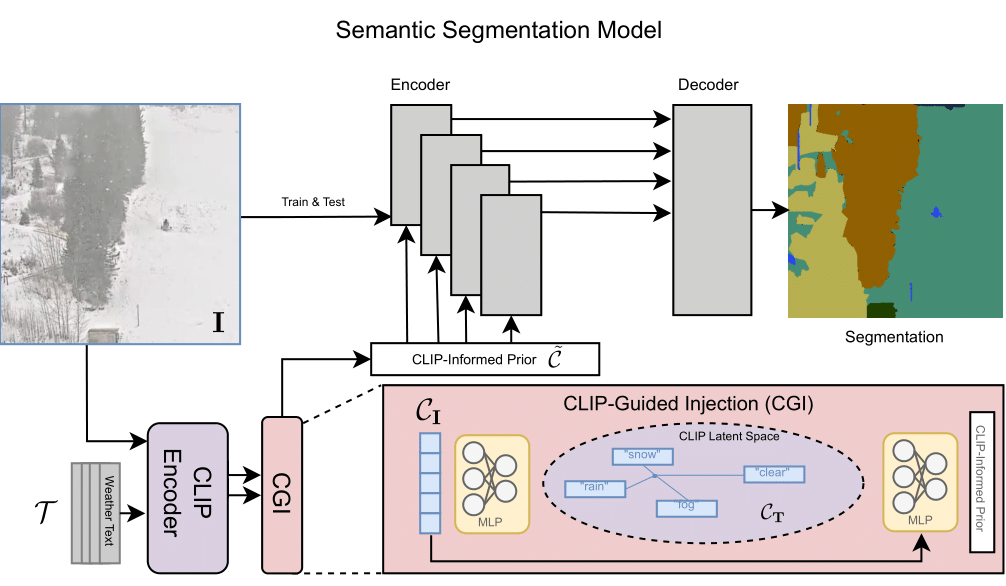
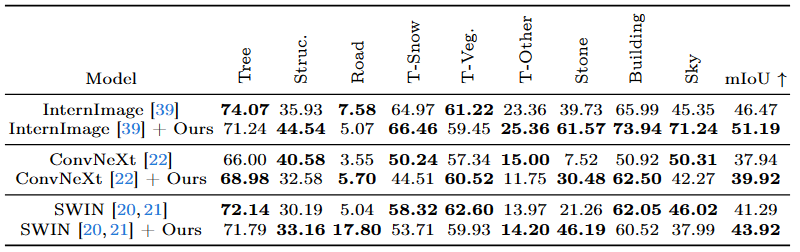
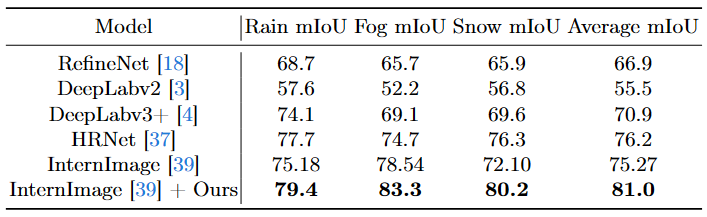
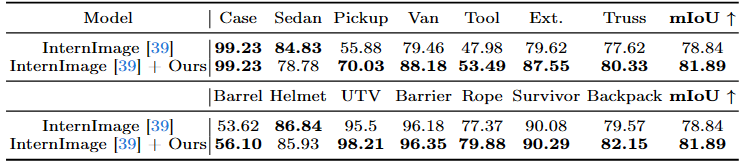
By using CLIP-based language guidance, models are able to generate features that are more resilient to adverse weather conditions. During training, a CLIP-Guided Injection module learns a CLIP-informed prior representing the adverse weather effect in the CLIP latent space. This is concatenated with the image latent before being fed in through cross-attention layers into the model.
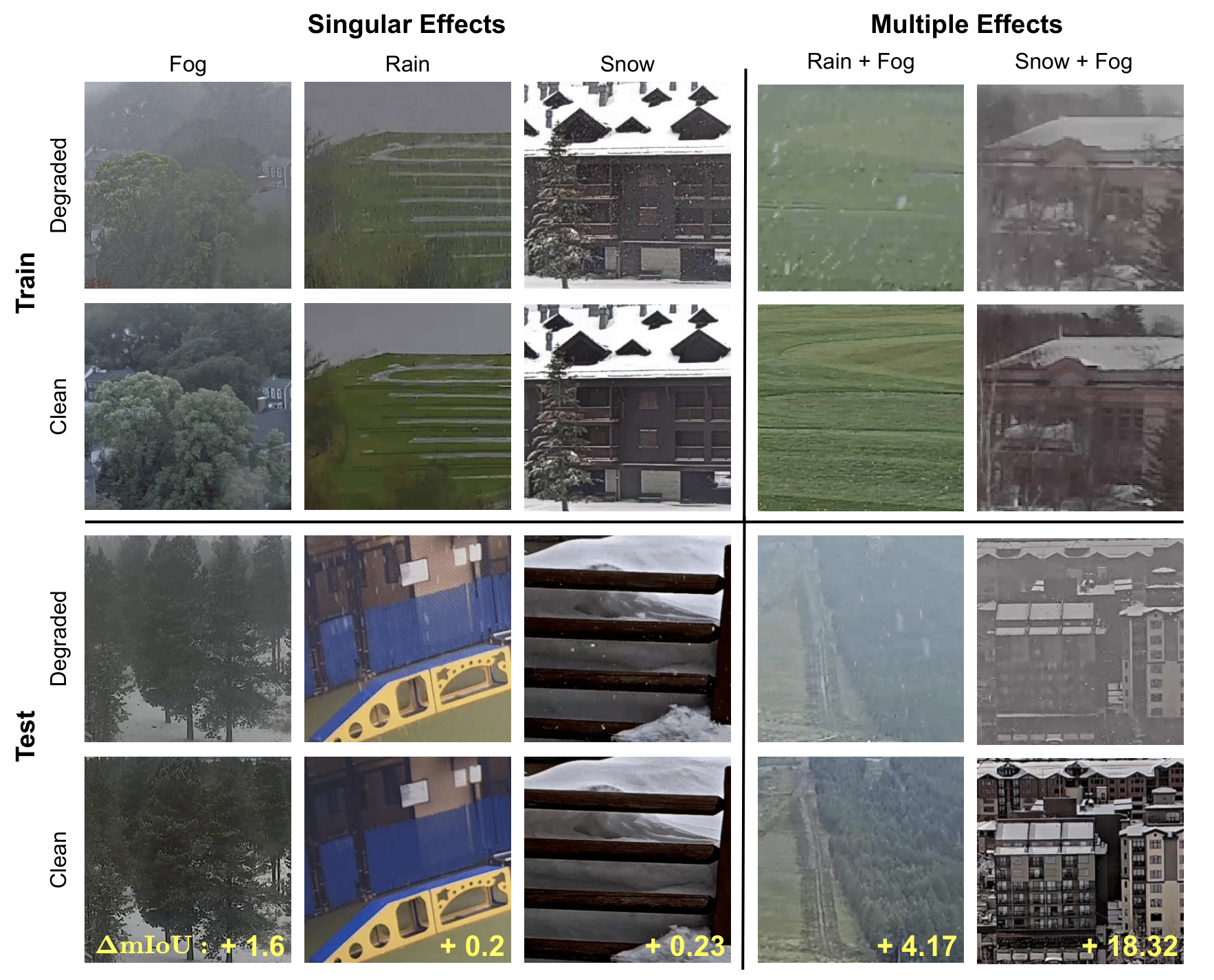
WeatherProof dataset contains accurate clear and adverse weather image pairs with 10 semantic classes. The dataset includes rain, snow, and fog weather effects. The labels below the image are for the WeatherProof dataset. In contrast, the ACDC [32] and IDD-AW [33] datasets’ paired images either have major differences in semantic information and scene structure or are not in RGB space.
The train and test sets of WeatherProof include paired sets of varied combinations of weather effects. Top: Various types of weather effects and their compositions from the training set. Bottom: Weather effects and combinations in our test set. Change in mIoU between clear and degraded images of the InternImage base- line is shown in yellow. Note the significant impact on mIoU results of multiple combined weather effects.